Abstract
Recent advances in large language models (LLMs) and dense retrievers have driven significant progress in retrieval-augmented generation (RAG). However, existing approaches face significant challenges in complex reasoning-oriented multi-hop retrieval tasks:
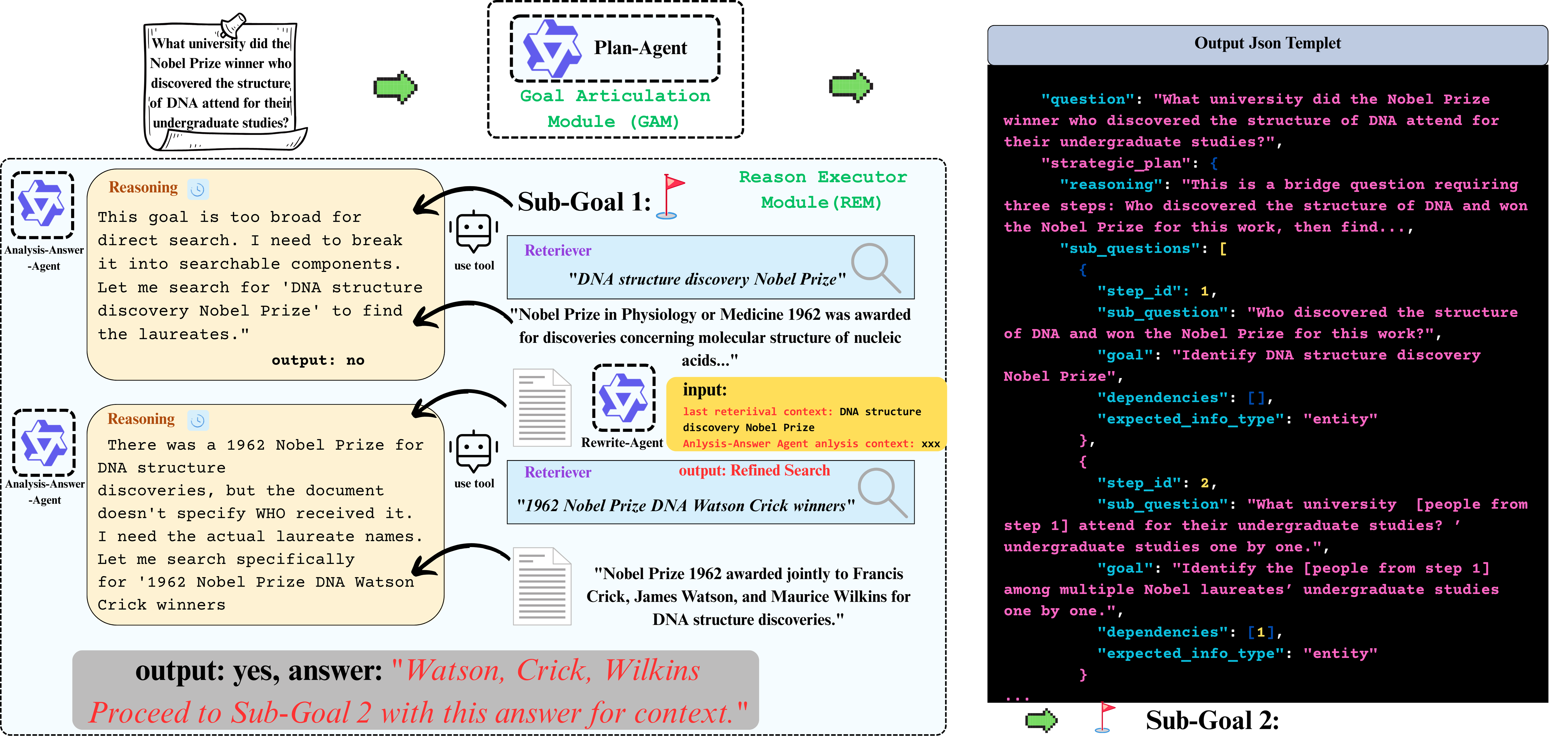
1) Ineffective reasoning-oriented planning: Prior methods struggle to generate robust multi-step plans for complex queries, as rule-based decomposers perform poorly on out-of-template questions.
2) Suboptimal reasoning-driven retrieval: Related methods employ limited query reformulation, leading to iterative retrieval loops that often fail to locate golden documents.
3) Insufficient reasoning-guided filtering: Prevailing methods lack the fine-grained reasoning to effectively filter salient information from noisy results, hindering utilization of retrieved knowledge.
Fundamentally, these limitations all stem from the weak coupling between retrieval and reasoning in current RAG architectures. We introduce the Orchestrated Planner-Executor Reasoning Architecture (OPERA), a novel reasoning-driven retrieval framework. OPERA's Goal Planning Module (GPM) decomposes questions into sub-goals, which are executed by a Reason-Execute Module (REM) with specialized components for precise reasoning and effective retrieval. To train OPERA, we propose Multi-Agents Progressive Group Relative Policy Optimization (MAPGRPO), a novel variant of GRPO. Experiments on complex multi-hop benchmarks show OPERA's superior performance, validating both the MAPGRPO method and OPERA's design.
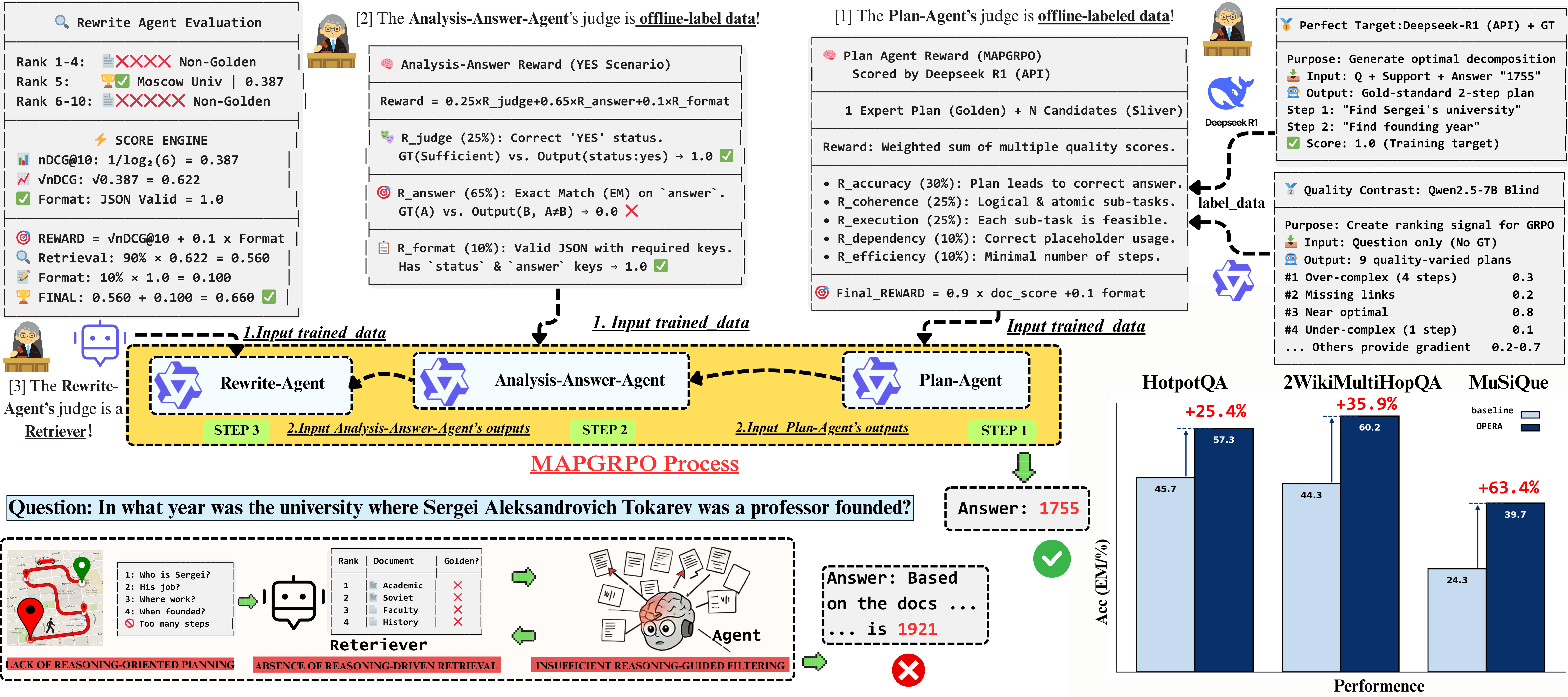
OPERA's MAPGRPO training framework and performance comparison